CUDA编程 (CUDA Programming)
2025年夏季InfiniTensor大模型与人工智能系统训练营
专业阶段
课程从零开始构建 GPU 并行计算思维,通过“问题驱动→分析瓶颈→优化实现→定量评估”的实战闭环逻辑,逐步深入 CUDA 核心知识与工业级优化技术。
讲师: 李梓民

课程内容简介
课程从零开始构建 GPU 并行计算思维,通过“问题驱动→分析瓶颈→优化实现→定量评估”的实战闭环逻辑,逐步深入 CUDA 核心知识与工业级优化技术。课程将深入 GPU 硬件架构与编程模型,并重点攻克性能瓶颈分析与调优:包括 Roofline 模型诊断算子的访存/计算瓶颈、内存合并与向量化优化、共享内存分块策略、Bank Conflict 规避、Swizzling 索引重构等关键技术。课程深度结合英伟达官方工具链(Nsight Compute/Systems)进行性能热点定位与优化验证。
在此之上,课程将扩展至系统级优化:通过多流并行、CUDA Graph 静态调度等实现计算-传输重叠,运用动态并行处理不规则任务,实践多 GPU 协同通信等。最后聚焦工业部署场景,涵盖低精度量化、 PTX 指令级调优和 CUDA 官方库应用等技能。
课程预期目标
通过本课程学员可以:
- 建立并行计算与高性能计算的思维逻辑,具备持续适应技术演进的核心能力;
- 具备从单一算子至多 GPU 环境运行的复杂系统的设计、实现与优化能力;
- 系统性的掌握 GPU 硬件架构、CUDA 编程模型、Nsight 性能工具使用以及工业级部署与调优能力;
- 具备业界所需的 CUDA 开发能力。
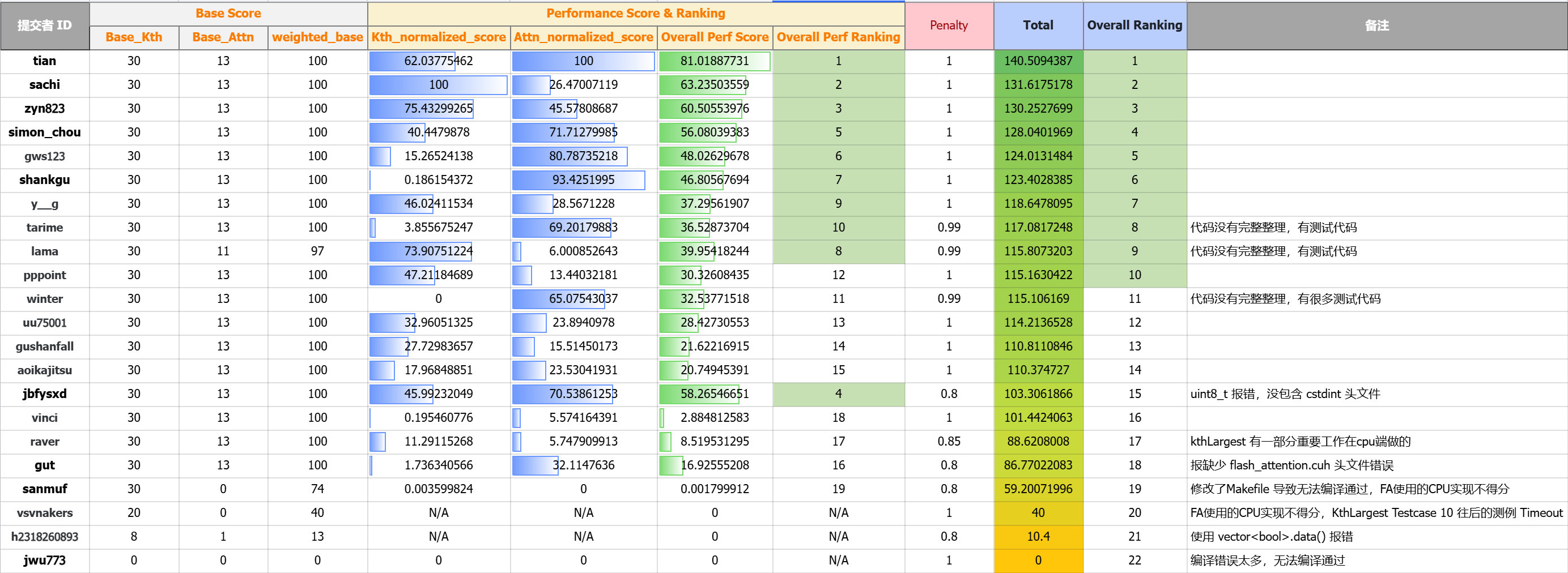
作业排行榜
学时
共 6 小时
课程依赖
无
预备知识
需 C++ 基础,最好有计算机体系结构的背景知识
授课方式
- 讲课
- 实验/实践
- 项目
课程详细情况
第一课时. “众人拾柴火焰高” —— 并行编程导论与 CUDA 入门
- 课时:1小时
- 前置依赖:无
第二课时. “墙壁上的行军图” —— 性能模型与逐元素优化
- 课时:1小时
- 前置依赖:无
第三课时. “从山巅到海床” —— 内存模型与规约优化
- 课时:1小时
- 前置依赖:无
第四课时. “乾坤大挪移” —— 分块与不规则访存
- 课时:1小时
- 前置依赖:无
第五课时. “时间折叠术”——异步并行、底层控制与系统优化
- 课时:1小时
- 前置依赖:无
第六课时. “精益求精” —— 量化与工业级调优部署
- 课时:1小时
- 前置依赖:无